5 Best Open Source Tools to Build End-to-End MLOps Pipeline in 2024


This article serves as a focused guide for data scientists and ML engineers who are looking to transition from experimental machine learning to production-ready MLOps practices. We identify the limitations of traditional ML setups and introduce you to essential MLOps open-source tools that can help you build a more robust, scalable, and maintainable ML system.
The tools discussed include Feast for feature management, MLflow for model tracking and versioning, Seldon for model deployment, Evidently for real-time monitoring, and Kubeflow for workflow orchestration.
Introduction to Open Source MLOps
The machine learning landscape is constantly changing, and the transition from model development to production deployment presents its own set of challenges. While Jupyter notebooks and isolated scripts are useful for experimentation, they often lack the features needed for a production-grade system. This article aims to help you navigate these challenges by introducing the concept of MLOps and a selection of open-source tools that can facilitate the creation of a production-ready ML pipeline.
Whether you're a data scientist looking to transition into production or an ML engineer seeking to optimize your existing workflows, this article aims to provide a focused overview of essential MLOps practices and tools.
Why Production-Grade ML is Different
Dynamic vs Static: Unlike experimental ML, which often uses fixed datasets, production environments are dynamic. They require systems that can adapt to fluctuating user demand and data variability.
Inelastic Demand: User requests in production can come at any time, requiring a system that can auto-scale to meet this inelastic demand.
Data Drift: Production systems need constant monitoring for changes in data distribution, known as data drift, which can affect model performance.
Real-Time Needs: Many production applications require real-time predictions, necessitating low-latency data processing.
The Traditional Machine Learning Setup
In a traditional machine learning setup, the focus is often on experimentation and proof-of-concept rather than production readiness. The workflow is generally linear and manual, lacking the automation and scalability required for a production environment.
Let's break down what this traditional setup usually entails, using a Credit Risk prediction model as an example:
- Data preprocessing and feature engineering are typically done in an ad-hoc manner using tools like Jupyter notebooks. There's usually no version control for the data transformations or features, making it difficult to reproduce results.
- The model is trained and validated using the same Jupyter notebook environment. Hyper-parameters are often tuned manually, and the training process lacks systematic tracking of model versions, performance metrics, or experiment metadata.
- Once the model is trained, predictions are run in batch mode. This is a manual step where the model is applied to a dataset to generate predictions, which are then saved for further analysis or reporting.
- The prediction results, along with any model artifacts, are manually saved to a data storage service, such as a cloud-based data store. There's usually no versioning or tracking, making it challenging to manage model updates or rollbacks.
You can picture this setup in the following image.

The Journey from Notebooks to Production: An Integrated ML System
While there's a wealth of information available on the MLOps lifecycle, this article aims to provide a focused overview that bridges the gap between a model in a Jupyter notebook and a full-fledged, production-grade ML system.
Our primary objective is to delve into how specific open-source tools can be orchestrated to create a robust, production-ready ML setup. Although we won't be discussing Kubernetes in detail, it's worth noting that the architecture we explore can be deployed on container orchestrators like Kubernetes for further scalability and robustness.
To ground our discussion, let's consider a real-world scenario: a data scientist is developing a predictive model for credit risk. The model relies on financial and behavioral data, which is housed in a Snowflake database but could just as easily reside in other data sources.
The following diagram illustrates an integrated ML system capable of real-time predictions. The subsequent sections will guide you through the transformation from a traditional ML setup to this more integrated, streamlined system. To achieve this, we'll introduce you to the top 5 open-source tools that are making waves in the industry today.

MLOps Open-Source Tools vs. Managed Platforms
In machine learning operations (MLOps), a pivotal decision organizations face is choosing between open-source tools and managed platforms. This choice significantly impacts how they build and manage their MLOps capabilities. Before delving into the specific open-source tools available for MLOps, it's important to briefly explore the benefits and drawbacks of these tools compared to managed platforms. The decision hinges on various factors, including the organization's specific needs, resources, and strategic goals.
MLOps Open Source Tools
Open-source tools in MLOps offer a high degree of flexibility and customization. This is particularly beneficial for teams with unique or evolving requirements that may not be well-served by a one-size-fits-all solution. Open-source tools allow you to tailor the software to meet the specific needs of your ML projects, whether it’s modifying the code to add new features or integrating with existing systems and tools.
A key benefit of open-source MLOps tools is cost-effectiveness. Many of these tools are free or incur minimal costs, making them accessible to organizations of all sizes. This can be particularly advantageous for startups and smaller teams with limited budgets.
Integration capabilities are another strong point of open-source MLOps tools. They are often designed to work well within a heterogeneous technology ecosystem, providing connectors and APIs for seamless integration with a variety of data sources, machine learning frameworks, and deployment environments.
Lastly, using open-source tools can offer significant opportunities for learning and skill development. Teams working with these tools are exposed to the latest technologies and practices in the field. This hands-on experience is invaluable for professional growth and staying abreast of the rapidly evolving MLOps landscape.
Managed MLOps Platforms
Provide a more streamlined and integrated approach. These platforms are typically easier to set up and use, offering a comprehensive suite of tools and services designed to work together seamlessly. This can significantly reduce the complexity and time involved in managing ML operations, making it an attractive option for teams with limited operational expertise or those looking to simplify their workflow.
The decision between open-source tools and managed platforms depends on various factors, including the size and expertise of your team, budget constraints, specific project requirements, and long-term strategic goals.
In the next sections, we’ll explore the five most important MLops Open-Source Tool categories:
1. Data Management and Feature Engineering
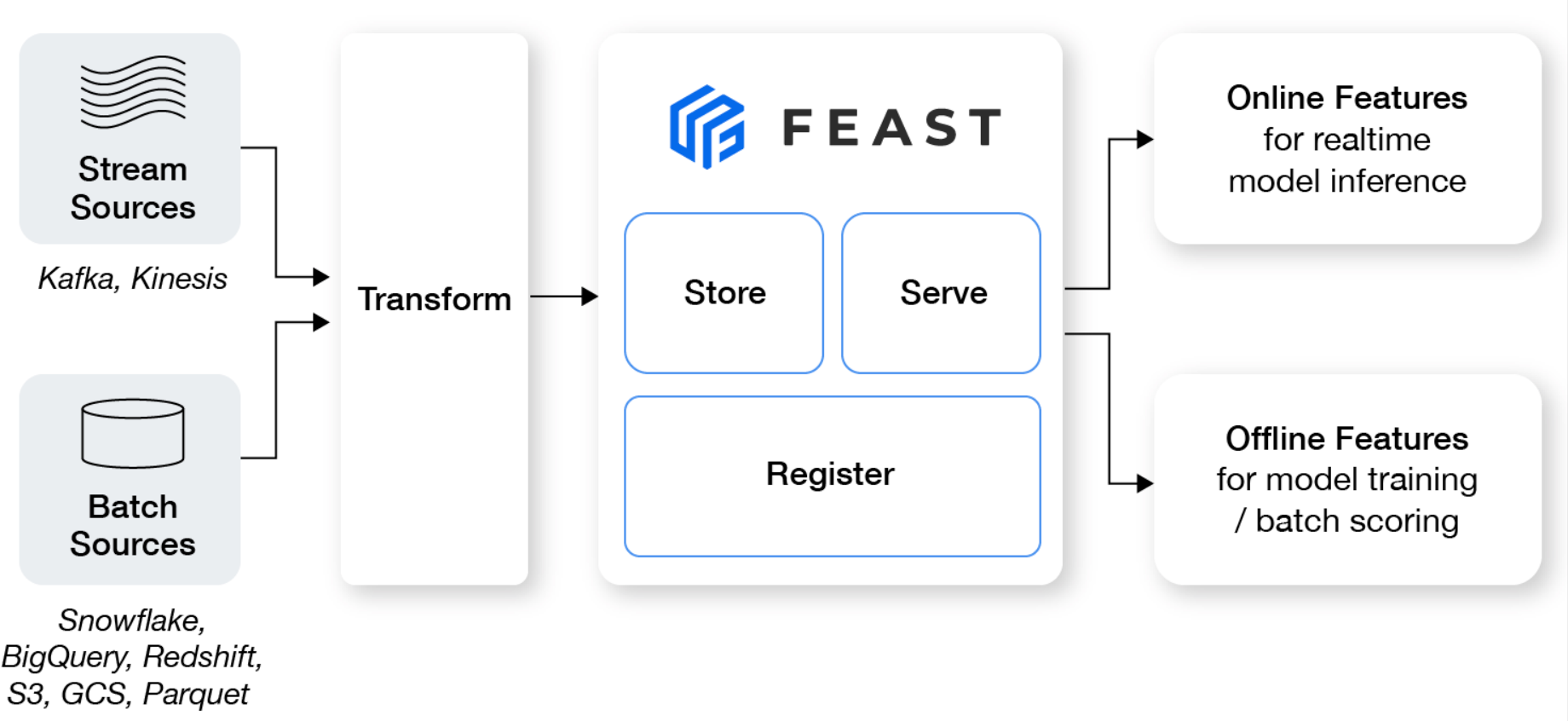
Managing and engineering features for machine learning models is a critical step that often determines the quality of the model. A feature store serves as a centralized hub for these features, ensuring that they are consistently managed, stored, and served.
What is a Feature Store?
A feature store is a centralized repository that acts as a bridge between raw data and machine learning models. It streamlines the feature engineering process and ensures consistency across different models. Feature stores can be broadly categorized into two types:
- Offline Feature Store - is primarily used for batch processing of features. It's where you store historical feature data that can be used for training machine learning models. The offline store is optimized for analytical workloads, allowing you to query large volumes of data efficiently. Typically, the offline feature store is backed by a data warehouse or a distributed file system like S3.
- Online Feature Store - serves features in real-time for model inference. When a prediction request comes in, the online feature store quickly retrieves the relevant features to be fed into the model. This is crucial for applications that require low-latency predictions. Online feature stores are often backed by high-performance databases like Redis to ensure quick data retrieval.
Additional Considerations When Adopting an Open Source Feature Store Solution
- Data Processing Infrastructure: Open source feature store solutions usually serve as an abstraction layer that integrates with your existing data infrastructure. For batch feature computation, tasks can be offloaded to an Apache Spark cluster, while real-time feature computation can be handled by a Kafka Streams application or Apache Spark Structured Streaming.
- Offline and Online Storage: Depending on the solution, you might need to set up and manage separate storage systems for both offline and online stores. The choice of storage systems should align with your workload requirements and existing infrastructure.
- Monitoring Infrastructure: Monitoring is crucial for maintaining data quality and operational efficiency. Integrating with external monitoring tools or building custom solutions might be necessary, especially for open-source feature stores that may not include comprehensive monitoring features.
Comparing Open-Source Feature Stores: Feast vs. Hopsworks
Feast: A Lightweight, Flexible Feature Store
- Data Access and Transformation: Feast connects to major data warehouses and lakes for batch data, and supports stream processing systems for real-time data. However, it requires pre-processed or transformed data for ingestion.
- Feature Storage and Serving: Feast relies on external systems for storing feature data and excels in both online and offline feature serving. It's designed for easy retrieval of feature data for training and inference.
- Monitoring: Feast doesn't include built-in monitoring, necessitating integration with external tools.
Best At: Feast is ideal for teams seeking a flexible feature store that integrates easily with existing cloud-native environments and ML workflows.
Hopsworks: An Integrated Data Science Platform
- Data Access and Transformation: Hopsworks can ingest data from a variety of sources, including real-time and batch data. It supports in-built feature transformation, offering a more comprehensive solution.
- Feature Storage and Serving: Hopsworks includes its own storage solutions for online and offline feature storage, as well as integrated feature serving capabilities.
- Monitoring: Offers more integrated monitoring capabilities than Feast, but may still require external tools for advanced monitoring.
Best At: Hopsworks is suited for organizations looking for an all-in-one solution that spans the entire lifecycle of feature management.
Our Tool Pick: Feast
For teams seeking a straightforward and flexible solution for managing and serving pre-processed features, Feast stands out as an ideal choice. Its integration-friendly nature makes it particularly well-suited for environments where ease of use and simplicity are key. While Hopsworks offers a more comprehensive and integrated platform, complete with in-built processing and storage capabilities for those needing a holistic feature management approach, Feast's streamlined and user-friendly design is recommended for teams prioritizing straightforward functionality and seamless integration.
2. Experiment Tracking and Model Versioning
In the dynamic world of machine learning, the ability to track experiments and version models is not just beneficial; it's a cornerstone of successful project management. These processes are akin to the detailed logging and version control systems in software development, but tailored specifically for the unique challenges of ML.
Experiment Tracking
Experiment tracking in ML is all about recording every detail during the model training phase - from the hyper-parameters used to the performance metrics obtained. This systematic approach is crucial for comparing experiments, refining models, and understanding why certain models perform better than others. For instance, tracking experiments can reveal how minor changes in data preprocessing can significantly impact model performance.
Model Versioning
Model versioning, often facilitated through a model registry, ensures that every iteration of an ML model is cataloged and retrievable. This practice is vital for maintaining a historical record of models, ensuring reproducibility, and streamlining the deployment process. Imagine being able to roll back to a previous model version effortlessly when a new version underperforms or introduces unexpected biases.
Additional Considerations for ML Experiment and Versioning Tools
- Storage Requirements: Efficient storage for detailed logs and large model files is essential. This could involve databases for experiment metadata and file storage systems for models.
- Operational Management: Beyond storage, considerations include server management, scalability, and ensuring high availability of these tools.
Comparing Open Source Tools for Experiment Tracking and Model Versioning
MLflow: Known for its simplicity and comprehensive tracking capabilities, MLflow offers a centralized dashboard for ML experiments. It excels in logging model artifacts and metadata and provides a model registry for version management.
- Experiment Tracking: MLflow provides an exceptional user experience for tracking experiments. It allows data scientists to log parameters, code versions, metrics, and output files, creating a rich, searchable database of all experiments.
- Model Management: With its centralized model store, MLflow excels in managing the entire lifecycle of ML models. This includes versioning, stage transitions (from staging to production), and annotations for easy identification and retrieval.
- Integration: MLflow is designed to play well with a wide range of ML libraries and platforms, making it a flexible choice for various tech stacks.
Best at: MLflow is particularly advantageous for teams that require comprehensive, intuitive solutions for managing the entire spectrum of machine learning experiments and model versions. It's suitable for both small-scale experiments and large-scale production deployments, offering tools that simplify complex ML workflows.
DVC (Data Version Control): DVC extends the concept of version control to data science projects. It focuses on versioning data and models, making it easier to track changes and collaborate on ML projects.
- Data & Model Versioning: DVC specializes in handling large data files and datasets. By tracking and versioning datasets, DVC helps manage data changes over time, ensuring that every dataset version is retrievable and reproducible.
- Pipeline Management: DVC enables the creation and management of reproducible and versioned data pipelines. This feature is particularly useful for complex workflows where the relationship between data changes and model performance needs to be clear and traceable.
- Git Compatibility: DVC is built to complement Git's capabilities, offering a solution for the version control of large files and datasets that are typically challenging for Git.
Best at: DVC is best suited for projects heavily reliant on accurate data versioning and robust pipeline management. It's ideal for teams that need a granular level of control over data changes and who are already comfortable working within the Git ecosystem.
Our Tool Pick: MLflow
MLflow emerges as the preferred tool for most ML teams, offering a harmonious blend of functionality and user-friendliness. It stands out for its comprehensive approach to experiment tracking and model versioning, coupled with its flexibility to integrate with various storage systems and ML workflows. This makes MLflow a versatile and valuable asset in the MLOps toolkit, suitable for a wide range of machine learning projects.
However, for the most comprehensive MLOps setup, consider leveraging the strengths of both tools. By integrating MLflow's experiment tracking and model management with DVC's data versioning and pipeline management, you can create a powerful, holistic approach to managing machine learning projects.
.jpg)
3. Model Deployment and Serving
After training and registering your ML model, the next critical step is deployment. While batch predictions are often executed offline where latency is less critical, real-time predictions demand low-latency responses to HTTP requests. Without deployment, an ML model remains just a theoretical construct; it's the deployment that brings it to life in a real-world context.
Model Deployment
In the journey of a machine learning model from development to real-world application, model deployment plays a critical role. This process involves integrating the trained model into a production environment, enabling it to make predictions or analyses based on new data. The deployment phase is increasingly streamlined with the integration of Machine Learning CI/CD pipelines. These practices automate crucial steps like testing, dependency management, and the actual deployment of the model, ensuring a smooth, reliable transition to a live environment.
Model Serving
Model serving is about making the deployed model accessible for practical use, typically through a web service. It involves setting up an infrastructure that receives incoming data requests, processes them through the model, and returns predictions. This can range from real-time predictions needed in instant decision-making scenarios to batch processing for larger datasets. Open-source model serving tools are designed to simplify this process. They offer features like handling multiple requests simultaneously, efficiently managing the load, and ensuring the model performs optimally under various operational conditions. These tools are crucial in operationalizing machine learning models, making them an integral part of the end-to-end machine learning workflow.
Additional Considerations When Adopting Model Serving Tools
- Container Orchestration Infrastructure: Before choosing a model serving tool, it's crucial to have a robust container orchestration infrastructure in place. This includes setting up and configuring platforms like Kubernetes to ensure smooth deployment and scaling of models.
- Infrastructure Autoscaling: Prior to selecting a serving tool, assess your infrastructure's ability to autoscale resources based on demand. Integration with auto-scaling services, especially in cloud environments, should be considered to optimize resource usage.
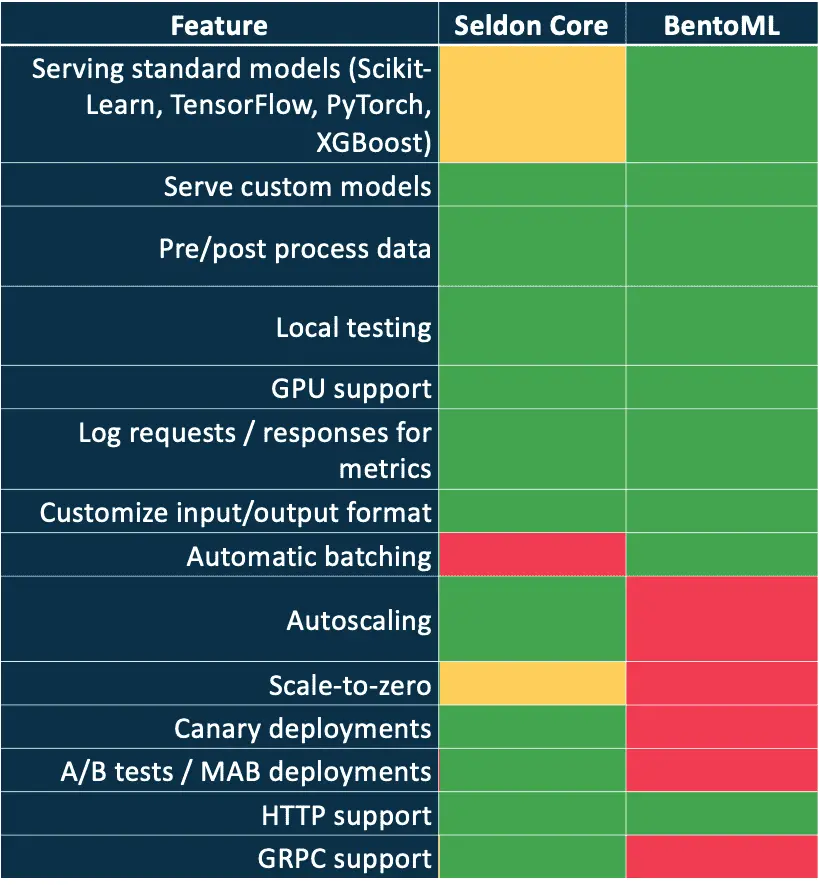
Comparing Open Source Tools for ML Model Serving: Seldon Core and BentoML
Seldon Core is another open-source tool designed for model serving. It offers a range of features tailored to complex deployment scenarios.
- Interfaces for Requests: Seldon Core provides native support for both HTTP and GRPC interfaces, providing flexibility in handling diverse types of requests. This versatility is advantageous for scenarios where different request/response formats or protocols are needed.
- Deployment Strategies: Seldon Core stands out in deployment strategies, offering advanced options like canary deployments, A/B testing, and Multi-Armed-Bandit deployments. These features make it a strong choice for complex deployment scenarios where testing different model versions and strategies is essential.
- Serving Custom Models: Similar to KServe, Seldon Core provides flexibility in serving custom models. It allows users to employ Docker images and offers an SDK for optional implementation. This flexibility extends to custom model support, making it suitable for a wide range of use cases.
- Monitoring Integration: Seldon Core integrates well with monitoring tools, including Prometheus. It provides extensive support for logging and analytics, making it ideal for detailed monitoring setups and diagnostics under various operational conditions.
- Request Batching and Input Customization: Seldon Core offers flexibility in configuring request batching to optimize serving performance. Custom input processing can also be implemented, providing users with control over how inputs are handled.
BentoML is a Python framework designed to simplify the deployment and serving of machine learning models. It offers a code-centric approach with extensive customization options.
- Interfaces for Requests: BentoML mainly supports HTTP for interfacing with models. While it focuses on HTTP-based services, handling other protocols may require custom code implementation.
- Deployment Strategies: BentoML offers a high degree of customization but requires manual setup for deployment. While it provides flexibility, it may involve more effort for implementing advanced deployment patterns.
- Serving Custom Models: BentoML's strength lies in its extensive customization capabilities. Users can leverage Python code to accommodate a wide range of custom models. This code-first approach allows for fine-grained control over the deployment process.
- Monitoring Integration: BentoML supports various monitoring and tracing tools, such as Jaeger and Prometheus. However, users may need to perform manual setup for detailed integration with these tools.
- Request Batching and Input Customization: BentoML supports automatic request batching, aiding in resource optimization. Additionally, its code-first nature provides
For a more detailed comparison of the tools mentioned above please refer to this getindata’s article.
Our Tool Pick: Seldon Core
Considering these aspects, Seldon Core emerges as our top choice. It balances robust functionality with operational agility, making it suitable for a broad spectrum of ML workflows. Seldon Core's support for complex deployment strategies, coupled with its Kubernetes-native architecture, renders it a versatile solution for businesses seeking to efficiently serve ML models at scale.
4. Model Monitoring
In a production environment, machine learning models interact with dynamic and constantly changing data. This fluidity necessitates vigilant monitoring to ensure that the model's performance remains consistent and reliable over time. Without proper monitoring, you risk model drift, data anomalies, and degraded performance, which could have significant business impact.
Additional considerations When Adopting OSS Model Monitoring Technologies
- Initial Data Flow Design: Before you even start collecting data, you'll need to architect a data flow that can handle both training and prediction data. This involves deciding how data will be ingested, processed, and eventually fed into Evidently for monitoring.
- Data Storage Strategy: Where you store this integrated data is crucial. You'll need a storage solution that allows for easy retrieval and is scalable, especially if you're dealing with large volumes of real-time data.
- Automated Workflows: Consider automating the data flow from model serving and your training data source to the monitoring tool. This could involve setting up automated ETL jobs or utilizing orchestration tools to ensure data is consistently fed into the monitoring tool.
Comparing Open Source Tools for ML Model Monitoring
evidently.ai is an open-source tool designed for comprehensive model monitoring. It provides real-time insights into model performance and data quality, helping you identify issues like model drift and anomalies as they occur. Evidently offers a straightforward setup with minimal configuration required for basic model monitoring.
- Out-of-the-Box Monitoring: "evidently.ai" primarily focuses on monitoring key metrics related to model predictions, data drift, and feature importance. Out of the box, it offers built-in capabilities to track metrics like accuracy, precision, recall, F1-score, and feature distribution shifts.
- Data Ingestion: Data ingestion in "evidently.ai" is straightforward. You typically provide a dataset and specify the target variable and prediction results. The tool then calculates various model performance metrics automatically.
- Configuration: Minimal configuration is required for basic monitoring. Users need to define the dataset and model prediction columns, but the tool handles the rest.
For example, suppose you have a binary classification model. With "evidently.ai," you simply input your dataset, specify the true labels, and the predicted probabilities or binary predictions. The tool automatically calculates metrics like accuracy, precision, recall, and F1-score.
Best at: evidently.ai excels at providing a simple and user-friendly approach to model monitoring, automating the calculation of common model performance metrics, and offering quick insights into model behavior. It's ideal for users who prioritize ease of use and want a straightforward solution for monitoring machine learning models. However, it may not be suitable for highly customized monitoring scenarios or large-scale deployments that require extensive customization and scalability.
Grafana + Prometheus is a monitoring and visualization duo. Prometheus collects data, and Grafana presents it visually through customizable dashboards. It's a flexible and scalable solution for monitoring various metrics across systems and applications.
- Out-of-the-Box Monitoring: Prometheus is a highly customizable monitoring system. It doesn't provide predefined model monitoring metrics out of the box. Instead, it excels at collecting and storing metrics from various sources, including model predictions, system performance, and more.
- Data Ingestion: Prometheus is designed to ingest data via exporters and scrape endpoints. For model monitoring, you would need to instrument your application to expose relevant metrics as Prometheus endpoints. Exporters for Python libraries like prometheus_client are commonly used for this purpose.
- Configuration: Setting up Prometheus for model monitoring is more involved. You need to define the metrics you want to collect, create exporters, and configure scraping intervals. Prometheus offers flexibility to monitor a wide range of metrics beyond model performance, making it suitable for custom monitoring needs.
Best at: Grafana with Prometheus shines in terms of customizability, scalability, and multi-source monitoring. It's well-suited for users who require extensive customization of monitoring metrics, are dealing with large-scale monitoring deployments, or need to monitor a variety of data sources beyond just models. Additionally, it offers robust alerting and anomaly detection capabilities. However, Grafana with Prometheus may not be the best choice for those seeking a simple and out-of-the-box solution or automated model metrics, as it involves a steeper learning curve and requires users to define and collect metrics themselves.
Our Tool Pick: evidently.ai
We choose "evidently.ai" for its out-of-the-box setup of predefined model monitoring metrics. Evidently comes with intuitive dashboards that make it easy to visualize and understand the model's performance metrics.

5. Machine Learning Workflow Orchestration
In MLOps, effective workflow orchestration is essential to streamline the integration of diverse components and processes. This orchestration involves not just managing data pipelines and model training, but also ensuring seamless integration with various tools and platforms.
Open Source Tools for ML Orchestration: Kubeflow
Kubeflow is an open-source platform optimized for the deployment of machine learning workflows in Kubernetes environments. It simplifies the process of taking machine learning models from the lab to production by automating the coordination of complex workflows. We specifically focus on Kubeflow in this discussion, as it uniquely offers a set of capabilities unmatched by any other single platform in machine learning orchestration.
Key Kubeflow Features:
- Support for Python: This is crucial as Python is predominantly the language of choice in the machine learning community.
- Training Operators: In Kubeflow, training operators are essential for managing machine learning model training jobs within a Kubernetes environment. These operators automate the deployment, management, and scaling of training jobs, simplifying the task for ML engineers and data scientists. They handle resource allocation, job scheduling, and ensure that the training process is resilient and efficient, even in distributed environments. This functionality is key to harnessing the full potential of Kubernetes for machine learning purposes, making the orchestration of complex ML workflows more manageable and streamlined.
- Notebooks: Provides an environment to spin up Jupyter notebooks for interactive development and data analysis.
- Native to Kubernetes: Designed to leverage Kubernetes' robust, scalable, and portable nature, making it suitable for handling complex machine learning workflows.
Integration with Other Open-Source MLOps Tools:
- MLflow Integration: Kubeflow and Airflow tasks can utilize MLflow's Python API to log parameters, metrics, and artifacts during the ML workflow, providing a comprehensive tracking mechanism.
- Seldon Core: For serving machine learning models, Seldon Core can be integrated into Kubeflow. You can deploy models trained in the Kubeflow pipeline using Seldon Core, which offers advanced features like canary deployments and scaling.
- Evidently AI: Incorporating tasks that trigger Evidently AI's monitoring and reporting can be part of the ML workflow, ensuring that your models are performing as expected and are reliable.
Additional considerations When Adopting Kubeflow for ML Workflows
- Kubernetes Expertise: Managing Kubeflow effectively requires a good understanding of Kubernetes. This includes knowledge of Kubernetes namespaces, RBAC, and other security features, which can add complexity to the management overhead.
- State Management: Kubeflow pipelines are stateless by default. If your workflows require stateful operations, you'll need to manage this yourself, adding to the complexity.
The following diagram can serve as a visual guide to understanding how Kubeflow orchestrates the various components in an ML workflow, including the feedback loop for continuous improvement.

Exploring Managed MLOps Solutions
While open-source tools offer flexibility and community support, they often come with the operational burden of setup, maintenance, and integration. One often overlooked aspect is the need for Machine Learning Engineering (MLE) skills within the organization to effectively utilize these tools. Additionally, the time required for full deployment of these open-source solutions can range from 3 to 6 months, a period during which models may be held back from production, affecting business objectives.
If you're looking for an alternative that combines the best of both worlds, managed MLOps platforms are worth considering.
One such platform is Qwak, which aims to simplify the MLOps lifecycle by offering an integrated suite of features. From feature management to model deployment and monitoring, Qwak provides a unified solution that can be deployed either as a SaaS or on your own cloud infrastructure. This allows you to focus more on model development and business impact, rather than the intricacies of tool management.
Conclusion
The transition from experimental machine learning to production-grade MLOps is a complex but necessary journey for organizations aiming to leverage ML at scale. While traditional setups may suffice for isolated experiments, they lack the robustness and scalability required for production environments. Open-source MLOps tools like Feast, MLflow, Seldon, and others offer valuable capabilities but come with their own set of challenges, including operational overhead and integration complexities.
Managed MLOps platforms like Qwak offer a compelling alternative, providing an integrated, hassle-free experience that allows teams to focus on what truly matters: building impactful machine learning models. Whether you're a data scientist looking to make the leap into production or an ML engineer aiming to streamline your workflows, the landscape of MLOps tools and practices is rich and varied, offering something for everyone.
By understanding the limitations of traditional setups and exploring both open-source and managed MLOps solutions, you can make informed decisions that best suit your organization's needs and take a significant step towards operationalizing machine learning effectively.
Say goodbye to complex AI/ML
Chat with us to see the platform live and discover how we can help simplify your AI/ML journey.